
What is Multi Task Learning?
Multi task learning is a subfield of machine learning that aims to solve several different tasks simultaneously, taking advantage of the similarities between other tasks. It can improve learning efficiency and act as a regulator that we will talk about in a moment.
Formally, suppose there are tasks (conventional deep learning approaches aim to solve a single task using one particular model). These tasks or a subset of them are related to each other but not identical. In that case, multitasking learning (MTL) will help improve the teaching of a particular model by using the knowledge contained in all tasks.
Applications of Multi Task Learning
Multi Task Learning techniques have found several uses, some of the main applications are:
- Object detection and facial recognition;
- Autonomous cars: pedestrians, stop signs, and other obstacles can detect together;
- Multi-domain collaborative filtering for web applications;
- Stock forecast;
- And also, language modeling and other NLP applications.
Methods of Multi Task Learning
So far, we have absorbed the theoretical motivations of MTL. To make MTL ideas more concrete, we’ll now take a look at the two most commonly used methods for multitasking learning in deep neural networks. In deep learning, multitasking learning usually involves the exchange of hard or soft parameters of hidden layers.
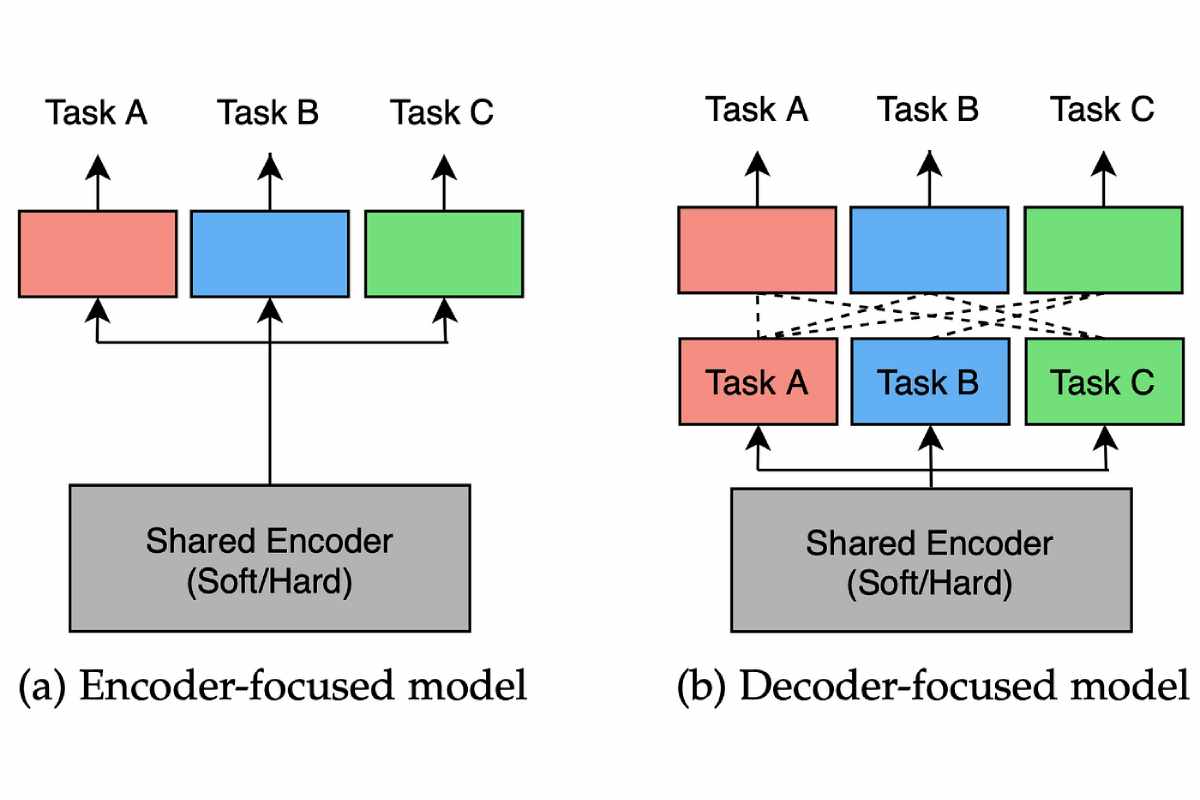
Sharing Hard Parameters
Strict parameter sharing is the most widely used approach for MTL in neural networks and dates back to. It is typically applied by sharing hidden layers between all jobs while maintaining multiple job-specific output layers.
Sharing strict parameters dramatically reduces the risk of overfitting. Indeed, he showed that the risk of overturning the shared parameters is of order N, where N is the number of tasks, lower than the over-tuning of the specific parameters of the study, that is to say, the output layers.
This makes intuitive sense: the more jobs we learn simultaneously, the more our model can find a representation that captures all the lessons. The less chance we have of oversizing our original mission.
Flexible Settings Sharing
On the other hand, with little settings sharing, each task has its marketing plan template with its settings. Then the distance between the model parameters is regularized to ensure that the parameters are similar. For example, it is using the ℓ2 norm for regularization while using the tracking norm.
The constraints used for sharing flexible parameters in deep neural networks were inspired mainly by MTL regularization techniques that develop for other models, which we will discuss shortly.
Why does Multi Task Learning Work?
Although an inductive bias obtained through multitasking seems intuitively plausible, to better understand MTL, one needs to look at the mechanisms behind it. Most of them first propose by Caruana (1998). We will assume that we have two related tasks, A and B, which base on a standard hidden layer representation for all the examples.
Implicit Data Augmentation
MTL effectively upsurges the sample size that we use to train our model. Since all tasks are at least somewhat noisy when introducing a model on task A, our goal is to learn a good representation for task A which ideally ignores data-dependent noise and generalizes well. Since different tasks have different noise models, a model that learns two lessons can discover a more general representation.
Warning
If a task is very noisy or if the data is limited and significant, it can be difficult for a model to differentiate between relevant and irrelevant characteristics. The MTL can help the model focus attention on the traits that matter, as other tasks will provide additional evidence of the relevance or irrelevance of those characteristics.
The easiest method to do this is by suggestion, that is, to directly train the model to predict essential characteristics.
Representation Bias
MTL skews the model to favor representations that other tasks also prefer. It will also help the model generalize to new functions in the future. A hypothesis space that works well for a sufficiently large number of training tasks will also work well to learn new lessons as long as they come from the same environment.
Regularization
Finally, Multi task learning acts as a regularizer by presenting an inductive bias. As such, it decreases the risk of overfitting and the Rademacher difficulty of the model. Its ability to adapt to random noise.
Conclusion
Multi task learning comes in many forms: co-learning, learning to learn. And learning with additional tasks just some of the names used to refer to it. Multi task learning uses successfully in machine learning applications, from natural language processing. And speech recognition to computer vision and drug discovery.
Generally, as soon as you find yourself enhancing more than one loss function, you effectively multitask (instead of single-task learning). These scenarios help to think about what you are trying to do explicitly in MTL terms and learn from it.