

What is Supervised Learning?
Supervised learning, also known as supervised machine learning, is a subcategory of machine learning and artificial intelligence. It defines using labeled data sets to train algorithms that accurately classify data or predict outcomes.
As input data enter into the model, the model adjusts its weights until the model fits correctly, which occurs as part of the cross-validation process. It helps organizations solve various natural, large-scale problems, such as sorting spam into a separate folder in your inbox.
How Supervised Learning Works?
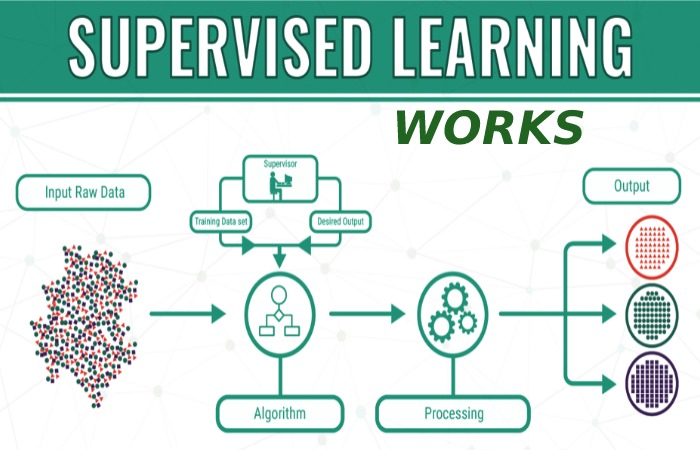
It uses a set of training to teach patterns to produce the desired outcome. This training data set includes correct inputs and outputs, allowing the model to learn over time. The algorithm measures its accuracy through the loss function, adjusting until the error sufficiently minimize.
It can divide into two types of problems when exploring data: classification and regression:
- Classification uses an algorithm to map test data into specific categories accurately. It recognizes particular entities within the dataset and tries to conclude how these entities should be labeled or defined.
- Standard classification algorithms are linear classifiers, support vector machines (SVMs), decision trees, nearest k-neighbor, and random forest, described in more detail below.
- Regression use to understand the relationship between dependent and independent variables.
- It commonly uses to make projections, such as the turnover of a particular company. Linear regression, logistic regression, and polynomial regression are popular regression algorithms.
Examples of Supervised Learning

Supervised learning models can be used to build and promote some business applications, including the following:
Image and Object Recognition: It algorithms can locate, isolate, and classify objects from videos or images, making them useful when applied to various computer vision and image analysis techniques.
Predictive Analytics: A widespread use case for models is building predictive analytics systems to provide detailed information on various business data points. This allows companies to anticipate specific outcomes based on a given output variable, helping business leaders justify their decisions or turn in the organization’s best interests.
Customer Sentiment Analysis: Using supervised machine learning algorithms, organizations can extract and categorize important information from large volumes of data, including context, emotions, and intent, with very little human intervention. This can be incredibly helpful in better understanding customer interactions and improving brand engagement efforts.
Spam Detection: Spam detection is another example of a supervised learning model. Using supervised classification algorithms, organizations can train databases to recognize patterns or anomalies in new data to efficiently organize spam and non-spam matches.
The Challenges of Supervised Learning
While it can offer benefits to companies, such as deep data insights and improved automation, there are some challenges in creating sustainable models. Here are some of those challenges:
- Its models may require certain levels of expertise to precisely structure.
- The formation of models can be time-consuming.
- Data sets may have a higher probability of human error, resulting in inadequate algorithm training.
- Unlike unsupervised learning models, it cannot group or categorize data on its own.
Unsupervised Learning vs. Supervised vs. Semi-supervised
Unsupervised machine learning and supervised machine learning frequently discuss together. Unlike, unsupervised learning which uses raw data. From this data, he discovers patterns that help solve clustering or association problems.
This is particularly useful when those skilled in the art are unsure of common properties within a data set. Standard clustering algorithms are hierarchical, k-means, and Gaussian mixture models.
Semi-supervised learning occurs when only a portion of the given input data label. Unsupervised and [semi-supervised learning] may be a more attractive alternative, as it can be time-consuming and expensive to rely on domain expertise to label data appropriately for it.
Conclusion
Supervised learning, as the name suggests, has a supervisor as a teacher. It is teaching or training the machine using well-labeled data. This means that some data already label with the correct answer.
After that, the apparatus receives a new set of examples (information) for the algorithm to analyze the training data (location of training examples) and produce a correct result from the labeled data.
Also Read: How to Move Office Tech Items Safely During a Move?